Perplexity vs Counsel
What an architecture gap actually looks like on the same AI-strategy decision
- Same decision text fed to both Perplexity and AIssential Counsel. Verbatim. No prompt tricks.
- Perplexity returned a sensible, well-structured answer with eight citations — almost all to vendor docs and evergreen blogs. Zero industry signal from 2026.
- Counsel returned five insights from a curated AI corpus of 273 candidates, each anchored to a literal quote from a recent source — CTO interview, TechCrunch on tokenmaxxing, O'Reilly on Specification-Driven Development.
- One of Counsel's five insights came with a warning: Counsel's own grounding verification flagged that two words in its synthesis could not be anchored in the source. Counsel told you it was not sure. Perplexity does not have an equivalent.
- The gap is not a prompt difference. It is generate-then-link vs. extract-then-synthesize. Stateless vs. persistent. No learning vs. six-layer feedback loop.
- Where Perplexity wins: breadth of topics, speed on one-off questions, no setup. Counsel does not compete on those.
If you have ever wondered whether you could just ask ChatGPT or Perplexity instead of paying for Counsel, this is the post for you. I ran the experiment.
Same decision text. Two tools. No prompt tricks. The answers came back fundamentally different — not because one was "better written" or had a "better prompt," but because the two tools have different architectures.
The setup
I fed both tools the same decision text, verbatim. Here it is:
Implementing AI-assisted workflows to enable both developers and non-developers (product / UX) to contribute to a SaaS codebase, while maintaining high code quality, ensuring understanding of changes, and minimizing developer overhead.
Constraints: small team size; need for clear contributing guides and conventions; non-developers require special care for code changes; existing tools are VS Code, GitHub, Claude; cannot push to production without full understanding of implementation and consequences; developers' time cannot be overly consumed by the process.
Then I asked: "Can you give me grounded elements to decide?"
Same words. Two tools. What came back tells you something about the architecture beneath each one.
Perplexity's answer
Perplexity returned a sensible, well-structured answer. The recommendation was correct as far as it went: "adopt AI-assisted workflows, but only with a constrained, review-heavy operating model."
The structure was clean:
- Five decision criteria — understandability before merge, small bounded diffs, protected merge path, explicit ownership, low developer overhead.
- A five-step operating model — non-devs write intent; Claude proposes implementation; developer reviews for architecture and consequences; branch protection blocks direct merge; non-devs only touch whitelisted areas.
- A list of what to put in the contributing guide.
- Red flags to watch for.
- A concrete recommendation — adopt AI for UI, copy, tests, docs, and isolated code paths; keep developer ownership for core logic, data model, integrations, and irreversibles.
Eight citations. And here is where the architecture starts to show.
Three of the eight citations point to docs.github.com pages about branch protection. Two more point to vendor support pages — code.claude.com and support.claude.com. One points to anthropic.com. Two more go to dev.to blog posts. The last one is a cloud.google.com blog post.
Look at what is missing: no recent industry signal. No CTO talking about what actually happened when their team adopted AI coding workflows. No 2026 paper measuring code churn rates against productivity. No build-vs-buy retrospective. Perplexity tapped vendor documentation and a few evergreen blog posts, then wrote a synthesis around them.
It closed with: "Would you like me to turn this into a decision matrix?"
Verdict. This is what an architecture that does generate-then-link produces. The LLM wrote the synthesis from its training memory plus a real-time web snippet pull. Then post-hoc citation matching attached plausible-looking sources. The citations are not load-bearing; they are decorative. Click through to docs.github.com/branch-protection and you will not find a recommendation about AI workflows — because the document is not about AI workflows. The link is attached because the synthesis mentioned branch protection, the system found a page about branch protection, and the two were related enough to display. The verification stops there.
Counsel's answer
Counsel is built around three persistent things you give it: decisions you are actively weighing (e.g. should we standardize on a Claude-based AI coding workflow across the team?), questions where you want the field's current evidence (e.g. what is the actual net productivity gain from agentic coding in 2026?), and monitored subjects you want to watch over time (e.g. Anthropic's coding-model roadmap). Each new generation re-checks every new article against all three lists, surfaces what bears most directly on each, and names the lists that had no signal. That persistent state is what a chatbot has no version of.
For the same AI-assisted workflows decision, Counsel produced a dated document with a lead, five insights, a "more in your areas" reserve, and a changes block since the previous generation.
The lead: "This week: Set Realistic AI Productivity Baselines — Developers generate 30% to 40% more code using AI, but 15% to 25% of that output requires rework or deletion."
The coverage stats: 269 semantic candidates considered → 160 final pool after dedup and judge gating → 11 articles cited. Newest article 1 day old. Median 43 days.
The five insights:
- Set Realistic AI Productivity Baselines — InfoQ keynote on AI copilots, 43 days old. Adjacent match, promoted from last run's reserve.
- Shift Alignment Before AI Code Generation — Maggie Appleton / GitHub YouTube keynote on collaborative AI engineering, 26 days old. Adjacent match, promoted from reserve.
- Adopt Specification-Driven AI Development — O'Reilly Radar, 63 days old. Direct match, carried from previous run.
- Formalize Intent as Machine-Readable Artifacts — O'Reilly Radar (IBM Bob piece), 44 days old. Direct match, carried.
- Mandate Small, Verifiable AI Pull Requests — Medium piece, 72 days old. Direct match, carried.
Each insight is structured: type (rule, finding, workflow, principle), one-sentence statement, three concrete bullets, an "applies when" clause, and — crucially — a "for your situation" field that names the user's actual constraints. For example, Insight 1's "for your situation" reads:
"Given your goal to enable both developers and non-developers, expect a 15–20% net gain for your engineering team while leveraging all-in-one tools to unlock massive new capabilities for your product and UX contributors."
Each insight also carries an evidence quote — the literal sentence from the source — plus a deep-link target (section ID and section title) so you can jump straight to the paragraph in the article. Insight 1's evidence quote is: "They estimated that net overall software engineer productivity gains about 15% to 20% productivity gains from AI."
All five insights on this run came back grounded: true with no unsupported claims. That is not always the case. On a previous generation of this exact decision, Counsel's grounding verification pass flagged its own paraphrase "Claude stack" as unsupported — the source video only said "standardize on one platform," and Counsel refused to anchor the more specific phrasing it had written into the published synthesis. Counsel surfaces its own uncertainty in the document itself. That is not a feature most chatbots have.
Then there is the rest of the document:
- A changes block comparing this run to the previous one: "2 promoted — AI-assisted Development is now active." Counts: 0 new, 3 carried, 2 promoted, 1 dropped. The dropped article is preserved in full so you can see what was demoted and why.
- Quiet areas dynamics. On the previous run, Non-developer Contribution Workflows and AI-assisted Development were both flagged as quiet with no signal in 90+ days. This run, fresh material on AI-assisted Development reactivated the area — Counsel reports the transition explicitly in the changes block, so you know what just woke up and what stayed silent.
- Five additional articles in the "More in your areas" reserve, with full takeaways — including a GitHub keynote by Maggie Appleton and an arXiv paper on AI-generated PR quality.
Verdict. This is what extract-then-synthesize produces. Counsel selected articles from a curated AI corpus, scored each against the user's actual decision text with an LLM judge, synthesized only from extracted passages, then ran a grounding verification pass before publishing — and surfaced the dynamics (what's new, what's silent, what just woke up) you can only build on top of persistent state.
The twelve differences, side by side
Here is the systematic comparison.
| # | Dimension | Perplexity | Counsel |
|---|---|---|---|
| 1 | Sources cited | 8 links: vendor docs + evergreen blogs | 11 articles from 2026 industry signal (CTO keynotes, GitHub talks, O'Reilly Radar, arXiv) |
| 2 | Citation-to-claim match | Decorative; attached after generation | Each insight cites a literal sentence from a deep-linked section |
| 3 | Self-flagged hallucinations | None — everything plausible is published | Each insight carries a grounding verification flag; unsupported phrases marked |
| 4 | Specificity of advice | Evergreen best-practices ("use branch protection") | 2026-specific framings ("track code churn", "Specification-Driven Development") |
| 5 | Use of user constraints | Reformulated in intro, forgotten in body | Each insight has a "for your situation" field naming the user's actual constraints |
| 6 | Architecture | Generate → search → attach citations | Search corpus → extract → judge → synthesize from passages → verify grounding → mark uncertainty |
| 7 | Absence detection | None | Quiet areas surfaced with "no signal in N days" |
| 8 | Inter-generation memory | None | Tracks new / carried / promoted / dropped vs. previous run; preserves dropped articles |
| 9 | Funnel transparency | None | Reports candidates evaluated → final pool → articles cited |
| 10 | Learning loop | None | Six-layer learning from explicit ratings + clicks + pins, recalibrating the per-user ranking and the LLM judge itself on your past examples |
| 11 | Output form | Disposable conversation + meta question | Dated, structured, versioned, shareable document |
| 12 | Stance | Centrist average of public opinion | Affirmative — and the contrary view is treated as a separate insight |
Read the table closely and you will notice that columns 3, 5, 7, 8, 9, and 10 are not features Perplexity is missing in version 1.0 and will ship in 2.0. They are features that require an architecture Perplexity does not have.
Why a better prompt cannot close the gap
If you have tried to close gaps like this with prompt engineering, you already know the limits.
A prompt cannot create state. No matter how cleverly you phrase a Perplexity query, the tool has no memory of your decisions, no list of what you ignored last week, no log of what you marked useful, no way to compare today's result to yesterday's. Every query starts from zero. That is the architectural truth behind "Counsel works when you do not ask" — without state, the tool can only react to your current question.
A prompt cannot create absence detection. To tell you that "agent framework: no signal in 41 days," the tool needs to know what you are tracking and to have been tracking it. That is two pieces of state, and neither is in a prompt.
A prompt cannot create a learning loop. Counsel's six-layer feedback system — per-URL semantic similarity, concept-level aggregation across topic / source / signal type, cross-user collective taste, click engagement, query-side embedding offset, and judge-LLM in-context calibration on your own positive and negative examples — compounds over weeks and months. A prompt operates within a single LLM call. When the call ends, there is no place for the learning to live.
A prompt cannot make extract-then-synthesize an architectural property. Even if you instruct ChatGPT or Perplexity to "only synthesize from the retrieved passages and do not fabricate," you are asking a system whose pipeline is generate, then attach citations to behave like a system whose pipeline is extract first, then synthesize from extracted structure. The first pipeline trusts the model to refrain from drawing on its training memory; the second pipeline does not give the model access to its training memory in the first place.
These are not negotiable through prompting. They are properties of the system around the LLM.
What Perplexity is actually better at
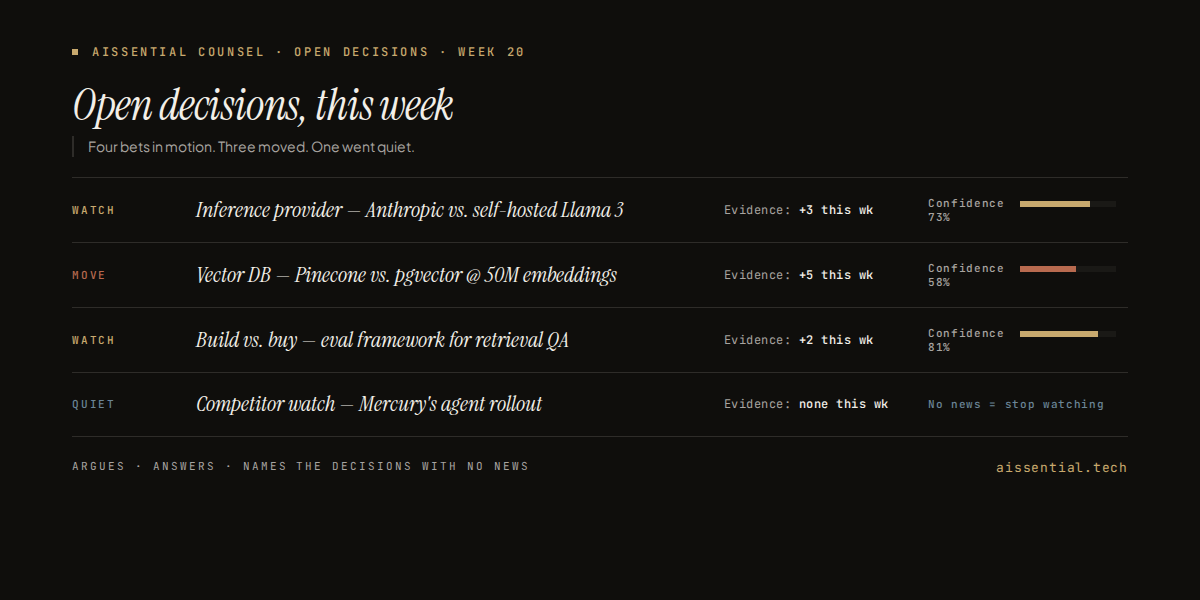
If we are going to be honest, the symmetric question matters too. Where does Perplexity win?
- Breadth of topics. Perplexity works on any topic. Counsel works on AI strategy decisions. If you want to know about EU tariff policy or the chemistry of a new battery technology, ask Perplexity, not Counsel.
- Speed on one-off questions. Counsel takes 30–60 seconds to generate a new document with verification, judging, and structured insight extraction. Perplexity gives you a useable answer in 5–15 seconds.
- No setup. Perplexity works the moment you sign up. Counsel needs you to name your decisions, your constraints, and your monitored subjects — which is the price of admission for the value the architecture delivers, but it is still a price you do not pay with Perplexity.
- Open-web freshness. Perplexity will pull a press release published this morning. Counsel reads from a corpus that gets refreshed on its own cadence (hourly to daily depending on the source tier).
None of this changes the gap on AI strategy decisions. It just frames where each tool fits.
The honest takeaway
If nothing real is riding on the answer — no decision on the line, no months of rework if you're wrong — use Perplexity or Claude. They will answer it.
If you have 1–3 active AI-strategy decisions on your plate — the kind where a wrong call costs three to six months of engineering, or a missed competitive move is the board meeting where your CEO knew first — and you want a tool that is tracking those decisions for you, naming the ones that have gone quiet, and re-checking every new article against them, the architecture gap matters.
That is the case Counsel was built to address.
Pricing and getting started
- Free — Daily Brief. 7 fresh, high-signal articles each morning, ranked by source tier, intent, and depth. Filter by your role, topics, and content type. Read in 5 minutes.
- €99/mo Solo (or €79/mo billed annually) — Daily Brief plus Counsel on every decision you bring. No slots, no math.
Expense it. No procurement. Sign up at aissential.tech →
Architecture, not prompting.
Make the AI decision you can defend.
Try AIssential for free →